Serverless applications on AWS with Lambda using Java 25, API Gateway and Aurora DSQL – Part 5 Using SnapStart with full priming
Introduction
In part 1, we introduced our sample application. In part 2, we measured the performance (cold and warm start times) of the Lambda function without any optimizations. We observed quite a large cold start time, especially if we use the Hibernate ORM framework. Using this framework also significantly increases the artifact size.
In part 3, we introduced AWS Lambda SnapStart as one of the approaches to reduce the cold start times of the Lambda function. We observed that by enabling SnapStart on the Lambda function, the cold start time goes down significantly for both sample applications.
In part 4, we introduced how to apply Lambda SnapStart priming technique, such as Aurora DSQL request priming. The goal was to even further improve the performance of our Lambda functions. We saw that by doing this kind of priming and writing some additional code, we could additionally reduce the Lambda cold start times compared to simply activating the SnapStart. It’s especially noticeable when looking at the “last 70” measurements with the snapshot tiered cache effect. Moreover, we could also reduce the maximal value for the Lambda warm start times by preloading classes (as Java lazily loads classes when they are required for the first time) and doing some preinitialization work (by invoking the method to retrieve the product from the Aurora DSQL products table by its ID). Previously, all this happened once during the first warm execution of the Lambda function.
In this article, we’ll introduce another Lambda SnapStart priming technique. I call it API Gateway Request Event priming (or full priming). We’ll then measure the Lambda performance by applying it and comparing the results with other already introduced approaches.
Sample application with JDBC and Hikari connection pool and the enabled AWS Lambda SnapStart using full priming
You can read more about the concepts behind the Lambda SnapStart in part 2 and about SnapStart runtime hooks (which we’ll use again) in part 3.
In this article, I will introduce you to the API Gateway Request Event priming (or full priming for short). We implemented it in the extra GetProductByIdWithFullPrimingHandler class.
I refer to part 4 for the explanation about how the Lambda SnapStart runtime hooks work. Please read my article Using insights from AWS Lambda Profiler Extension for Java to reduce Lambda cold starts, on how I came up with this idea. I also described in this article in detail why it is supposed to speed things up. Shortly speaking, we primed another expensive LambdaEventSerializers.serializerFor invocation. It consists of class loading and expensive initialization logic, which I identified. By invoking handleRequest, we fully prime this method invocation, which consists mainly of Aurora DSQL request priming introduced in part 4. At the end, we also prime the APIGatewayProxyResponseEvent object construction.
In our example, we primed the APIGatewayProxyRequestEvent “get product by id equal to zero” request. This is enough to instantiate and initialize all we need, even if we’d like to invoke the “create product” request. This priming implementation is also a read request without any side effects. But if you’d like, for example, to prime a “create product” request, you can do it as well:
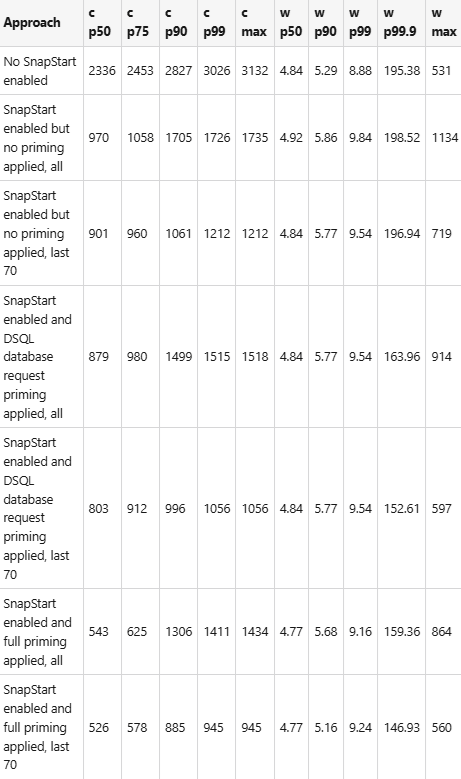
Measurements of cold and warm start times of the Lambda function of the sample application with JDBC and Hikari connection pool
We’ll measure the performance of the GetProductByIdJava25WithDSQLAndFullPriming Lambda function mapped to the GetProductByIdWithFullPrimingHandler shown above. We will trigger it by invoking curl -H “X-API-Key: a6ZbcDefQW12BN56WEDQ25” https://{$API_GATEWAY_URL}/prod/productsWithFullPriming/1.
Please read part 2 for the description of how we designed the experiment.
I will present the Lambda performance measurements with SnapStart being activated for all approx. 100 cold start times (labelled as all in the table), but also for the last approx. 70 (labelled as last 70 in the table). With that, the effect of the snapshot tiered cache, which we described in part 3, becomes visible to you.
To show the impact of the SnapStart full priming, we’ll also present the Lambda performance measurements from all previous parts.
I did the measurements with java:25.v19 Amazon Corretto version, and the deployed artifact size of this application was 17.150 KB.
Cold (c) and warm (w) start time with -XX:+TieredCompilation -XX:TieredStopAtLevel=1 compilation in ms:
Sample application with Hibernate and Hikari connection pool and the enabled AWS Lambda SnapStart using full priming
We’ll reuse the sample application from part 1 and do exactly the same performance measurement as we described in part 2.
We implemented the full priming in the extra GetProductByIdWithFullPrimingHandler class.
The explanation of what we would like to achieve and how is exactly the same as in the first sample application above. And the code itself looks the same.
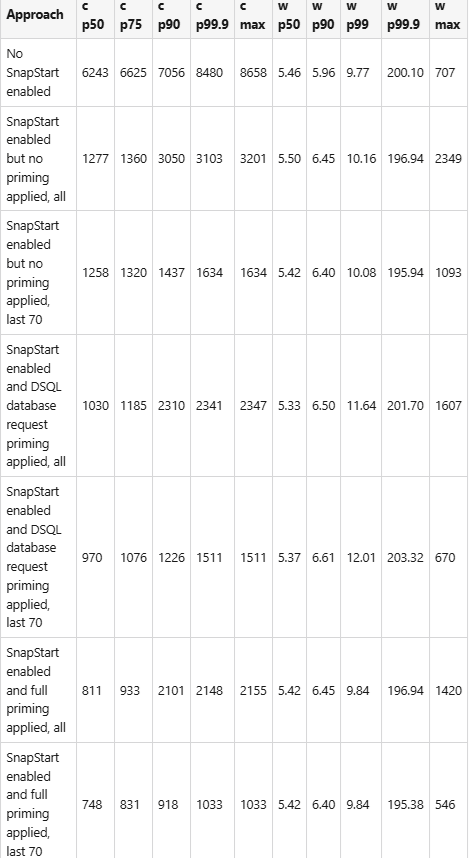
Measurements of cold and warm start times of the Lambda function of the sample application with Hibernate and Hikari connection pool
We’ll measure the performance of the GetProductByIdJava25WithHibernateAndDSQLAndFullPriming Lambda function mapped to the GetProductByIdWithFullPrimingHandler shown above. We will trigger it by invoking curl -H “X-API-Key: a6ZbcDefQW12BN56WEHADQ25” https://{$API_GATEWAY_URL}/prod/productsWithFullPriming/1.
Please read part 2 for the description of how we designed the experiment.
To show the impact of the SnapStart full priming, we’ll also present the Lambda performance measurements from all previous parts.
I did the measurements with java:25.v19 Amazon Corretto version, and the deployed artifact size of this application was 42.333 KB.
Cold (c) and warm (w) start time with -XX:+TieredCompilation -XX:TieredStopAtLevel=1 compilation in ms:
Conclusion
In this part of the series, we introduced how to apply another Lambda SnapStart priming technique. I call it API Gateway Request Event priming (or full priming). The goal was to even further improve the performance of our Lambda functions. We saw that by doing this kind of priming and writing even more additional (but simple) code, we could further reduce the Lambda cold start times compared to simply activating the SnapStart and doing Aurora DSQL request priming. It’s once again especially noticeable when looking at the “last 70” measurements with the snapshot tiered cache effect. Moreover, we could again reduce the maximal value for the Lambda warm start times by preloading classes and doing some preinitialization work.
It’s up to you to decide whether this additional complexity is worth the Lambda function performance improvement. You could also be happy with its performance using Lambda SnapStart with the Aurora DSQL request priming.
Please also watch out for another series where I use a NoSQL serverless Amazon DynamoDB database instead of Aurora DSQL to do the same Lambda performance measurements.